Python + ComfyUI:打造自动化AI绘画工作流
简介
ComfyUI 是一个功能强大的AI绘画工具,能够帮助用户快速生成高质量的图像。然而,在实际应用中,用户往往需要在工作流执行前后对输入图像进行预处理或后处理,例如调整尺寸、添加滤镜或进行格式转换。此外,用户可能希望自动从ChatGPT获取创意提示词来生成更具个性化的图像,或者将输出的图片按照特定的文件夹结构进行整理,以便于管理和检索。或者,用户可能希望将ComfyUI与聊天软件集成,通过简单的对话指令触发图像生成流程。凭借Python的灵活性和丰富的生态系统,用户可以轻松实现这些功能,打造高度自动化、智能化的AI绘画工作流,满足多样化的创作需求。
使用说明
ComfyUI不限定版本,笔者使用的是秋叶启动器2.8.12;
保证你使用的工作流能够正常出图,python并不解决无模型、内存不足等问题;
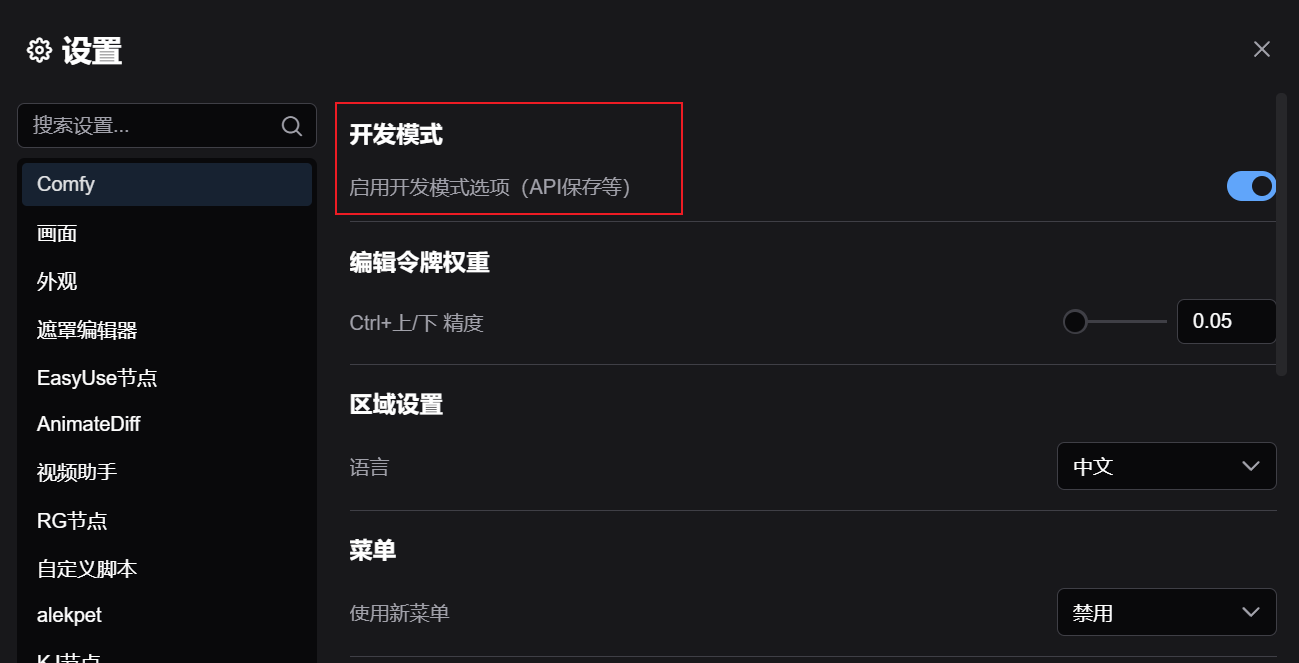
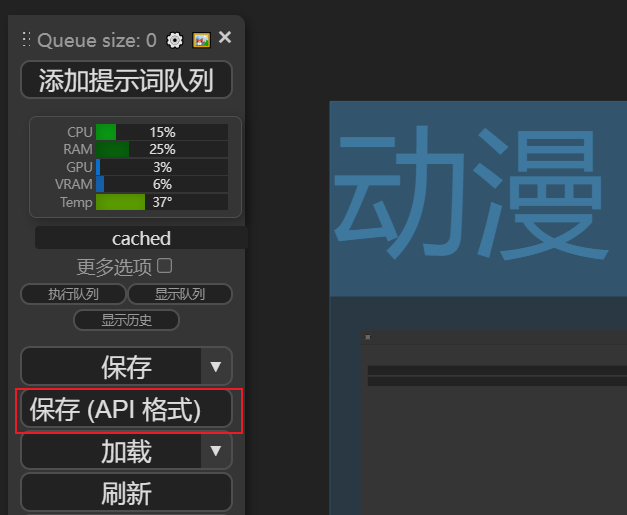
将ComfyUI切换到开发者模式,保存工作流的API文件;
代码
整体框架(图生图):
上传图片到ComfyUI服务器,返回图片路径;
在工作流中填充图片路径和随机种子;
上传工作流并获取返回的任务id;
等待任务结束,根据任务id拿到历史数据;
根据历史数据拿到图片并保存。
上传图片
def upload_image(filepath):
filename = os.path.basename(filepath)
new_filepath = upload_folder + filename
with open(filepath, "rb") as image_file:
image_binary_data = image_file.read()
files = {'image': (new_filepath, image_binary_data, 'image/png')}
response = requests.post(f"http://{server_address}/upload/image", files=files)
if response.status_code == 200:
return new_filepathupload_image接收图片的路径,然后将图片上传到ComfyUI的upload_folder文件夹下,接着返回了上传图片的路径。
解析并上传工作流
def queue_prompt(prompt):
p = {"prompt": prompt, "client_id": client_id}
data = json.dumps(p).encode('utf-8')
req = urllib.request.Request(f"http://{server_address}/prompt", data=data)
return json.loads(urllib.request.urlopen(req).read())
def parse_workflow(filepath, workflow):
with open(workflow, 'r', encoding="utf-8") as workflow_api:
prompt = json.load(workflow_api)
# 设置图片输入
for node in input_nodes:
prompt[str(node)]["inputs"]["image"] = filepath
# 设置噪声
for node in noise_nodes:
new_seed = generate_seed()
if "noise_seed" in prompt[str(node)]["inputs"]:
prompt[str(node)]["inputs"]["noise_seed"] = new_seed
elif "seed" in prompt[str(node)]["inputs"]:
prompt[str(node)]["inputs"]["seed"] = new_seed
else:
pass
# 获取任务id
prompt_id = queue_prompt(prompt)['prompt_id']
return get_images(prompt_id)parse_workflow将图片路径和随机种子填充到工作流中。input_nodes为输入节点列表、noise_nodes为噪声节点列表。每个工作流的input_nodes和noise_nodes都不同,需要自行查找,方法如下:
(关键步骤)在ComfyUI的web界面中找到工作流的输入节点,节点序号一般在右上角,添加到input_nodes中;

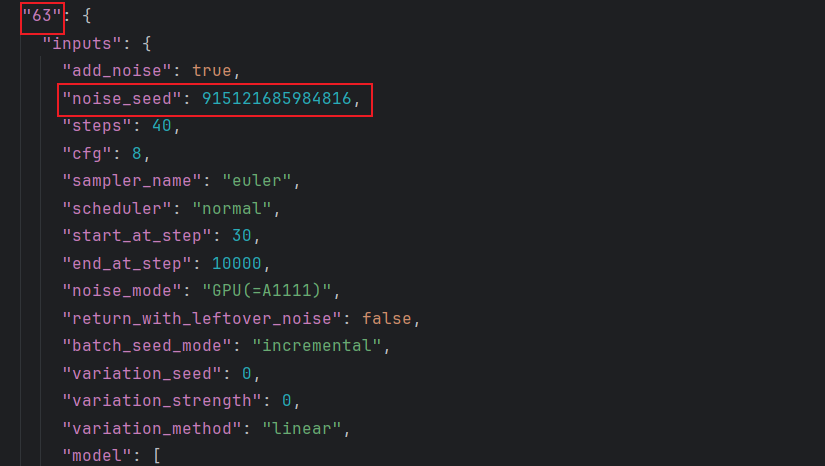
(关键步骤)在API文件中搜索seed关键字,如果有noise_seed或seed字段,就将这个节点序号添加到noise_nodes中。
获取历史数据并解析图片
def get_history(prompt_id):
with urllib.request.urlopen(f"http://{server_address}/history/{prompt_id}") as response:
return json.loads(response.read())
def get_images(prompt_id):
ws = websocket.WebSocket()
ws.connect(f"ws://{server_address}/ws?clientId={client_id}")
logger.info('prompt_id:{}'.format(prompt_id))
output_images = {}
while True:
out = ws.recv()
if isinstance(out, str):
message = json.loads(out)
if message['type'] == 'executing':
data = message['data']
if data['node'] is None and data['prompt_id'] == prompt_id:
logger.info(f"prompt_id:{prompt_id} 任务已完成")
break
else:
continue # 预览为二进制数据
history = get_history(prompt_id)[prompt_id]
for o in history['outputs']:
if o in output_nodes:
images = history['outputs'][o]['images']
images_output = []
for image in images:
image_data = get_image(image['filename'], image['subfolder'], image['type'])
images_output.append(image_data)
output_images[o] = images_output
logger.info(f"prompt_id:{prompt_id} 获取图片成功")
return output_imagesget_images打开了一个websocket连接,持续监听ComfyUI的任务完成情况,如果任务已经完成,就获取历史数据并按照给定的output_nodes获取输出图片。
(关键步骤)在ComfyUI的web界面中找到工作流的输出节点,节点序号一般在右上角,添加到output_nodes中;
完整实现
import json
import os
import random
import requests
import websocket
import uuid
import urllib.request
import urllib.parse
from loguru import logger
def generate_seed():
return random.randint(10 ** 14, 10 ** 16 - 1)
# 定义一个函数向服务器队列发送提示信息
def queue_prompt(prompt):
p = {"prompt": prompt, "client_id": client_id}
data = json.dumps(p).encode('utf-8')
req = urllib.request.Request(f"http://{server_address}/prompt", data=data)
return json.loads(urllib.request.urlopen(req).read())
# 定义一个函数来获取图片
def get_image(filename, subfolder, folder_type):
data = {"filename": filename, "subfolder": subfolder, "type": folder_type}
url_values = urllib.parse.urlencode(data)
with urllib.request.urlopen(f"http://{server_address}/view?{url_values}") as response:
return response.read()
def upload_image(filepath):
filename = os.path.basename(filepath)
new_filepath = upload_folder + filename
with open(filepath, "rb") as image_file:
image_binary_data = image_file.read()
files = {'image': (new_filepath, image_binary_data, 'image/png')}
response = requests.post(f"http://{server_address}/upload/image", files=files)
if response.status_code == 200:
return new_filepath
# 定义一个函数来获取历史记录
def get_history(prompt_id):
with urllib.request.urlopen(f"http://{server_address}/history/{prompt_id}") as response:
return json.loads(response.read())
# 定义一个函数来获取图片,这涉及到监听WebSocket消息
def get_images(prompt_id):
ws = websocket.WebSocket()
ws.connect(f"ws://{server_address}/ws?clientId={client_id}")
logger.info('prompt_id:{}'.format(prompt_id))
output_images = {}
while True:
out = ws.recv()
if isinstance(out, str):
message = json.loads(out)
if message['type'] == 'executing':
data = message['data']
if data['node'] is None and data['prompt_id'] == prompt_id:
logger.info(f"prompt_id:{prompt_id} 任务已完成")
break
else:
continue # 预览为二进制数据
history = get_history(prompt_id)[prompt_id]
for o in history['outputs']:
if o in output_nodes:
images = history['outputs'][o]['images']
images_output = []
for image in images:
image_data = get_image(image['filename'], image['subfolder'], image['type'])
images_output.append(image_data)
output_images[o] = images_output
logger.info(f"prompt_id:{prompt_id} 获取图片成功")
return output_images
# 解析工作流并获取图片
def parse_workflow(filepath, workflow):
with open(workflow, 'r', encoding="utf-8") as workflow_api:
prompt = json.load(workflow_api)
# 设置图片输入
for node in input_nodes:
prompt[str(node)]["inputs"]["image"] = filepath
# 设置噪声
for node in noise_nodes:
new_seed = generate_seed()
if "noise_seed" in prompt[str(node)]["inputs"]:
prompt[str(node)]["inputs"]["noise_seed"] = new_seed
elif "seed" in prompt[str(node)]["inputs"]:
prompt[str(node)]["inputs"]["seed"] = new_seed
else:
pass
# 获取任务id
prompt_id = queue_prompt(prompt)['prompt_id']
return get_images(prompt_id)
# 生成图像并显示
def generate(workflow, upload_path):
filename = os.path.basename(upload_path)
filepath = upload_image(upload_path)
images = parse_workflow(filepath, workflow)
for node_id in images:
idx = 1
for image_data in images[node_id]:
from datetime import datetime
timestamp = datetime.now().strftime("%m%d%H%M%S")
# 使用格式化的时间戳在文件名中
output_img_path = f"{output_folder}{node_id}_{filename}_{idx}_{timestamp}.jpg"
with open(output_img_path, "wb") as binary_file:
binary_file.write(image_data)
idx += 1
logger.info(f"{output_img_path} 保存完毕")
def process_images(input_folder, workflow):
for filename in os.listdir(input_folder):
filepath = os.path.join(input_folder, filename)
if os.path.isfile(filepath) and filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
for i in range(repeat_times):
generate(workflow, filepath)
if __name__ == "__main__":
# 输入输出文件夹
upload_folder = "./upload/"
output_folder = "./output/"
input_folder = "./input/"
# ComfyUI地址
COMFYUI_ENDPOINT = '127.0.0.1:8188'
server_address = COMFYUI_ENDPOINT
# 工作流API文件
workflow = '动漫转真人.json'
# 输入输出节点
input_nodes = ['112']
output_nodes = ['94']
noise_nodes = ['63', '65', '83']
# 其他设置
repeat_times = 1
if not os.path.exists(output_folder):
os.makedirs(output_folder)
if not os.path.exists(input_folder):
os.makedirs(input_folder)
client_id = str(uuid.uuid4())
process_images(input_folder, workflow)
logger.info("任务已完成")再次提醒:
这是一份用于图生图的代码,如果要实现文生图或者其他功能,请自行修改;
代码中需要自行修改COMFYUI_ENDPOINT、input_nodes、output_nodes和noise_nodes;
输入的文件放到input文件夹下,输出的文件会保存到output文件夹中;